Set Up n8n + Ollama: Free Local LLMs on your laptop in 10 mins
Learn to set up n8n with Ollama's free local LLMs on your laptop in just 10 minutes. Complete step-by-step guide with Docker setup, AI model installation, and building your first conversational AI agent - no API costs, complete privacy.


Tired of monthly ChatGPT API bills for your n8n workflows? In the next 10 minutes, you'll have n8n running with completely free local LLMs via Ollama.
No internet required, your data stays private, and it costs nothing to run.
This guide will walk you through setting up the complete stack on Windows or Mac. By the end, you'll have n8n workflows powered by local AI that never sends your data anywhere.
What You're Building
A powerful local automation setup where:
- n8n handles your workflow automation (like Zapier, but more flexible)
- Ollama runs AI models locally on your laptop
- Llama 3.2 1B provides lightning-fast AI responses for your workflows
Why this combination works:
- Complete privacy - nothing leaves your laptop
- Zero ongoing costs after setup
- Works offline - best for extensive testing
Follow Step By Step. Subscribe for more Quick AI Workflows.
Prerequisites: Install Docker (2 minutes)
Before we start, you need Docker Desktop installed on your computer.
Windows
- Download Docker Desktop from https://www.docker.com/products/docker-desktop/
- Run the installer and follow the setup wizard
- Restart your computer when prompted
- Launch Docker Desktop - you should see the Docker whale icon in your system tray
Mac
- Download Docker Desktop from https://www.docker.com/products/docker-desktop/
- Open the downloaded .dmg file and drag Docker to Applications
- Launch Docker from Applications
- You should see the Docker whale icon in your menu bar
How do you know Docker is ready?
- The Docker icon should be visible in your system tray (Windows) or menu bar (Mac)
- The icon should not have any warning symbols
- You can click on it and see "Docker Desktop is running"
Part 1: Set Up n8n with Docker (3 minutes)
Why Docker?
Think of Docker as a pre-configured box that contains everything n8n needs to run perfectly. No complex installations or dependency issues.
Windows Setup
Step 1: Make sure Docker Desktop is running (you should see the Docker whale icon in your system tray)
Step 2: Open PowerShell and run this command:
docker run -it --rm --name n8n -p 5678:5678 -v "${PWD}\data:/home/node/.n8n" n8nio/n8n:latest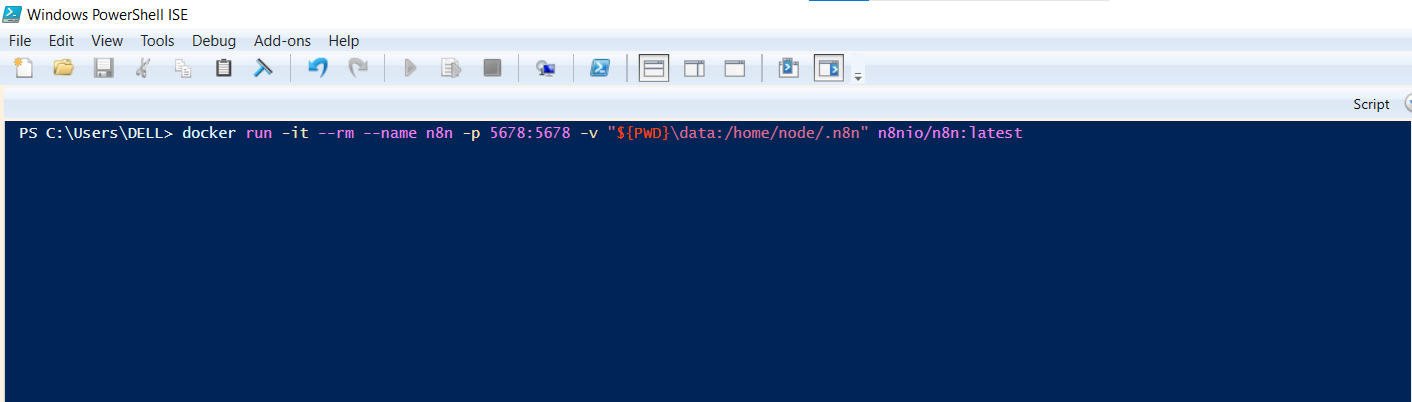
What this command does:
- Downloads and runs n8n in a container
- Makes it accessible at
localhost:5678 - Saves your workflows to a
datafolder in your current directory
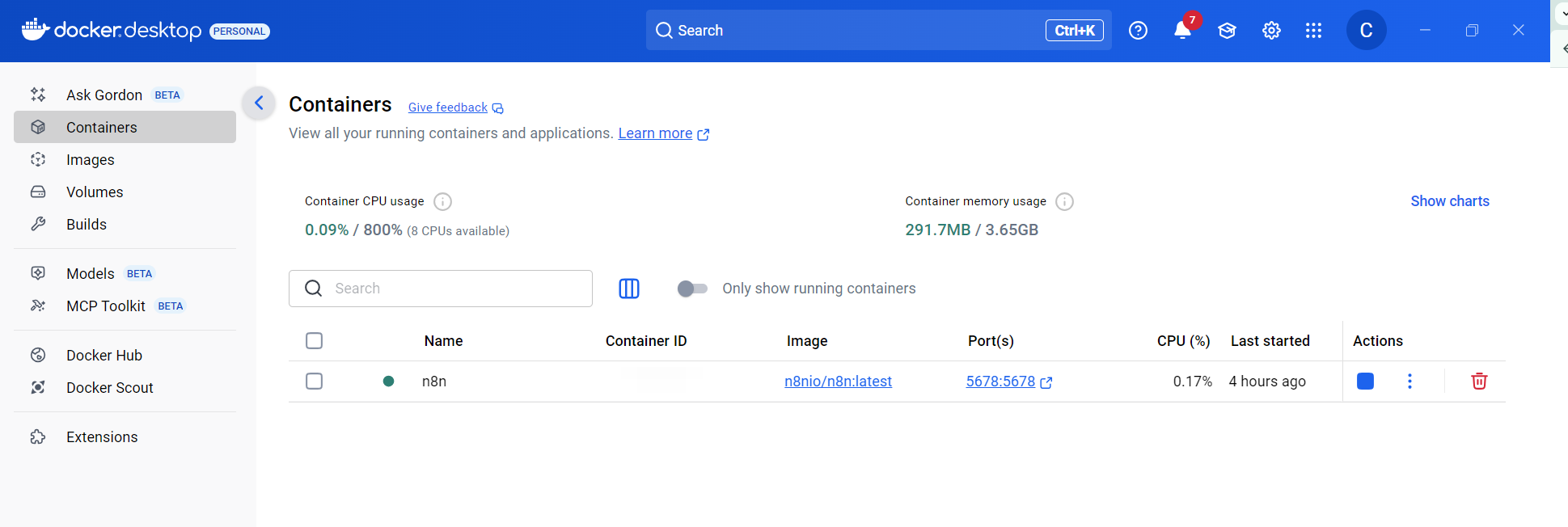
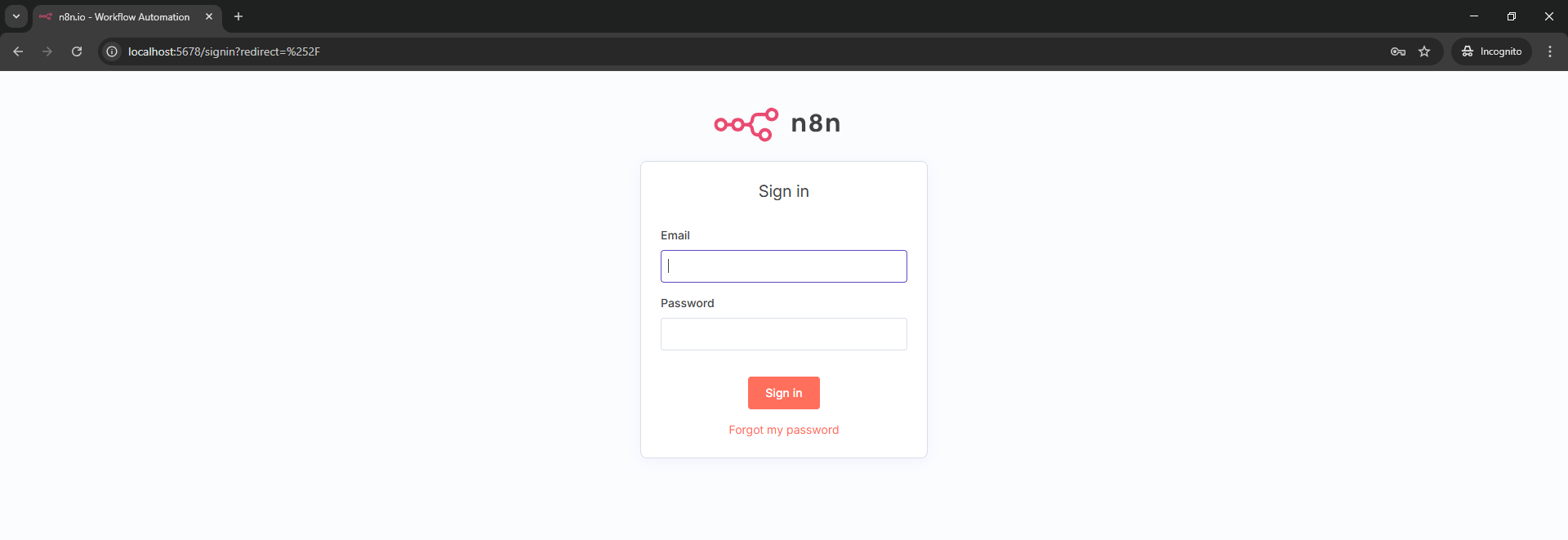
Step 3: Open your browser and go to http://localhost:5678
You should see the n8n welcome screen! Create your account when prompted.
Mac Setup
Step 1: Make sure Docker Desktop is running
Step 2: Open Terminal and run:
docker run -it --rm --name n8n -p 5678:5678 -v "$(pwd)/data:/home/node/.n8n" n8nio/n8n:latestStep 3: Open your browser and go to http://localhost:5678
Part 2: Install Ollama and Download the AI Model (4 minutes)

Why Llama 3.2 1B?
This model is perfect for automation tasks:
- Ultra-fast: 40-50 responses per second
- Lightweight: Only needs 3GB RAM
- Smart enough: Handles data extraction, categorization, and decision-making perfectly
- Small download: Just 1.3GB
Some other models that you can consider for running locally:
| Model | Speed | Memory Required | Download Size | Best For |
|---|---|---|---|---|
| Llama 3.2 1B (Recommended) |
⚡⚡⚡⚡ 40-50 tokens/sec |
3GB RAM | 1.3GB | Fast automation, data extraction, quick responses |
| Llama 3.2 3B | ⚡⚡⚡ 25-35 tokens/sec |
6GB RAM | 2GB | Better reasoning, complex conversations |
| Phi-3 Mini | ⚡⚡ 15-25 tokens/sec |
8GB RAM | 2.2GB | Code generation, technical tasks |
| Qwen2.5 1.5B | ⚡⚡⚡ 30-40 tokens/sec |
4GB RAM | 0.9GB | Multilingual, small footprint |
| Gemma2 2B | ⚡⚡⚡ 20-30 tokens/sec |
5GB RAM | 1.6GB | Google's model, good balance |
Windows Installation
Step 1: Download Ollama from https://ollama.com/download/windows
Step 2: Run the installer (it takes about 1 minute)
Step 3: Open a new PowerShell window and run:
ollama pull llama3.2:1bThe model will download (1.3GB) and Ollama will start running automatically in the background.
Mac Installation
Step 1: Download Ollama from https://ollama.com/download/macos
Step 2: Run the installer (it takes about 1 minute)
Step 3: Open Terminal and run:
ollama pull llama3.2:1bHow do you know it's working?
- Windows: You'll see Ollama in your system tray
- Mac: You'll see Ollama in your menu bar
- Both: The download completes without errors
Part 3: Connect n8n to Ollama (3 minutes)
Here's the crucial part that trips up most people: n8n running in Docker can't talk to Ollama using the normal localhost address.
The following steps have a simple fix.
Create Your First AI Workflow
Step 1: In n8n, click "New Workflow"

Step 2: Add a Chat Trigger node
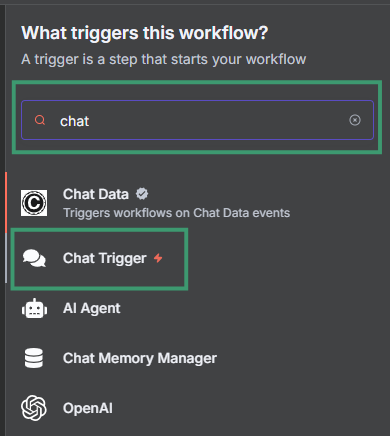
- Search for "Chat Trigger" in the nodes panel
- This creates a web interface where you can chat with your AI
Step 3: Add an AI Agent node
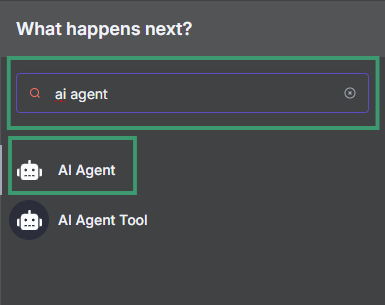
- Search for "AI Agent" and drag it to your canvas
- Connect the Chat Trigger to the AI Agent
Step 4: Add an Ollama Chat Model node
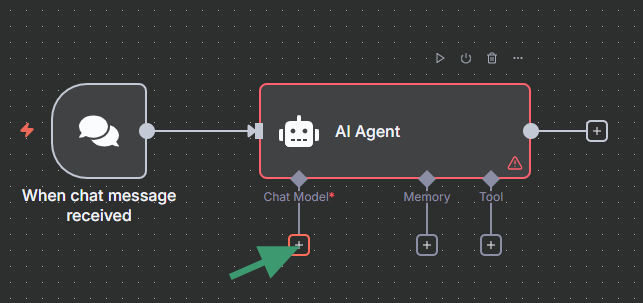
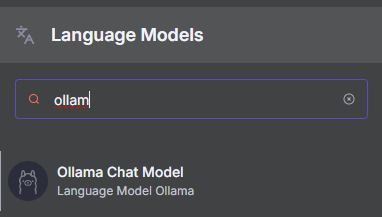
- Search for "Ollama Chat Model"
Step 5: Configure the Ollama connection
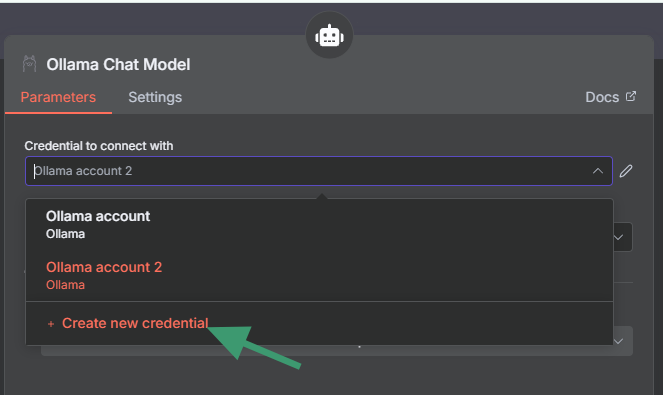
- Click on the Ollama Chat Model node
- Click "Create new credential"
- Set the Base URL to:
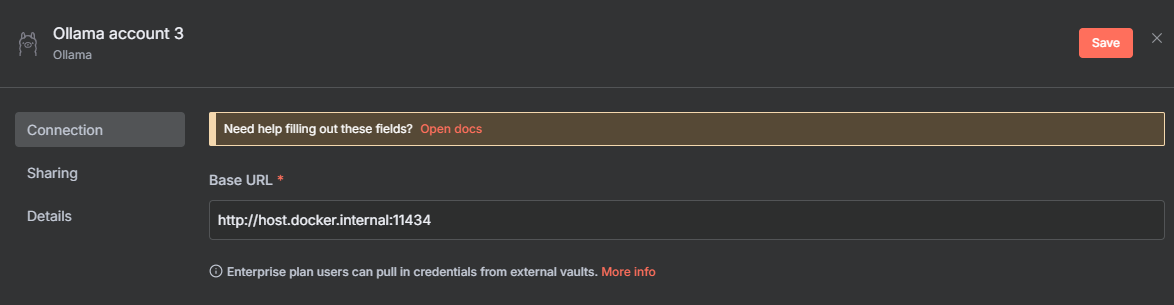
http://host.docker.internal:11434- Click "Save" and then "Test connection"
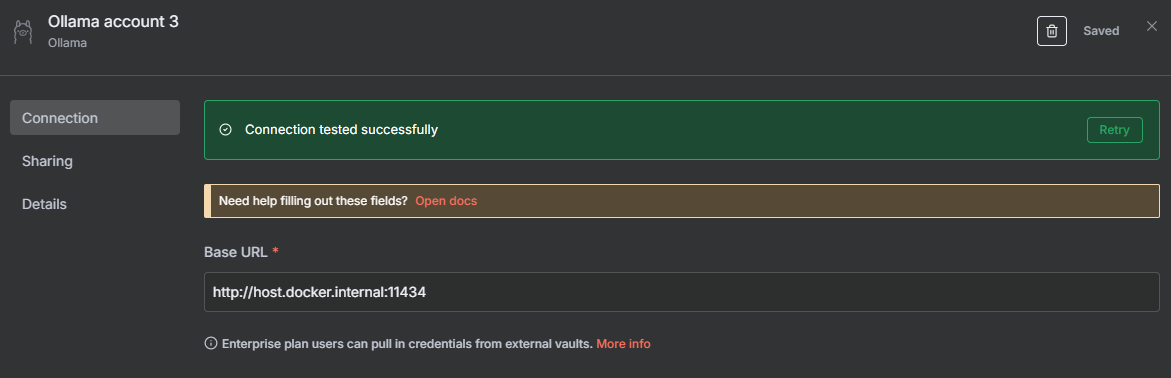
- You should see "Connection successful!"
Why This Address Works (and not the default one)
The address host.docker.internal is Docker's way of letting containers (n8n) talk to services running on your actual computer (Ollama). Think of it as a special bridge between the Docker container and your laptop.
Step 7: Configure the model settings
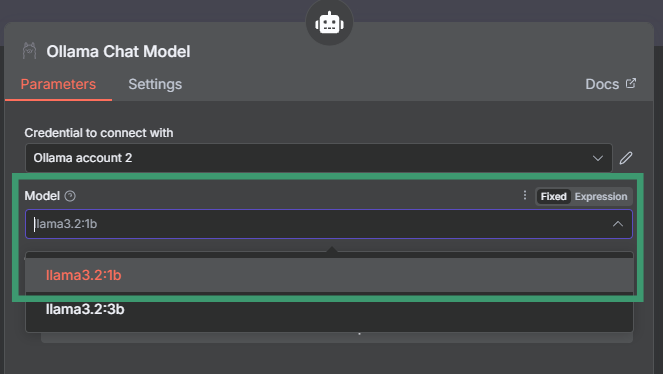
- In the Ollama Chat Model node, set Model to
llama3.2:1b - Leave other settings as default
Step 6: Add a Simple Memory node
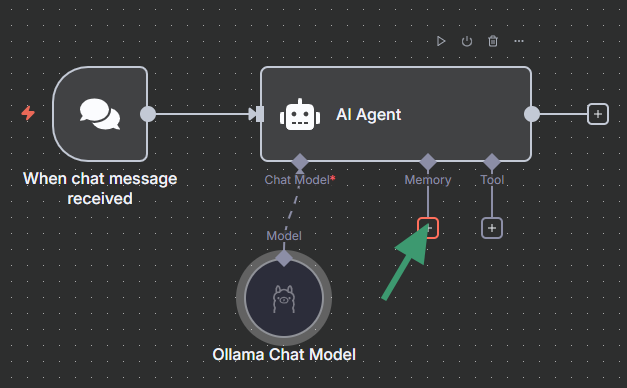
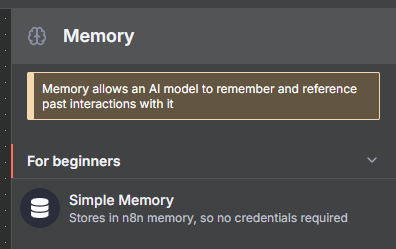
- Search for "Simple Memory"
- This lets your AI remember the conversation
Step 8: Connect everything together
- In the AI Agent node, connect:
- Language Model → Select your Ollama Chat Model
- Memory → Select your Simple Memory node
Test Your AI Agent
Step 9: Click "Test workflow" in the top right
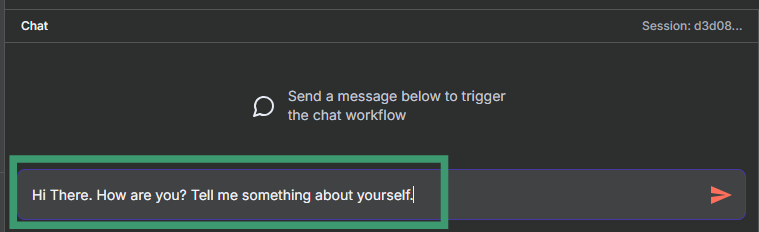
Step 10: You'll see a chat interface appear. Try asking:
- "Hello, what can you help me with?"
- "Remember my name is John. What's my name?"
- "Help me write an email to a customer"
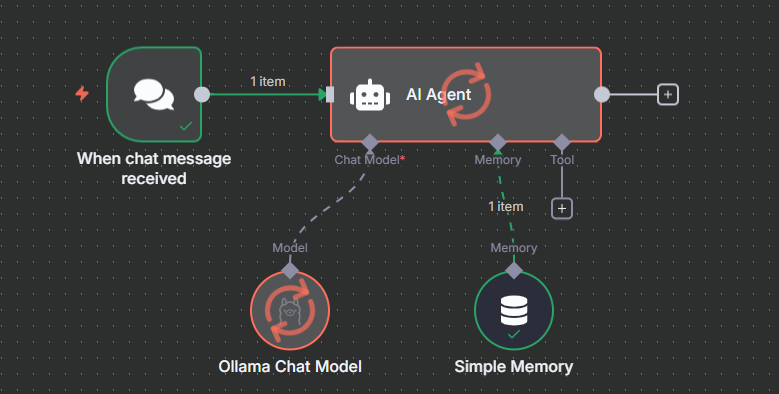
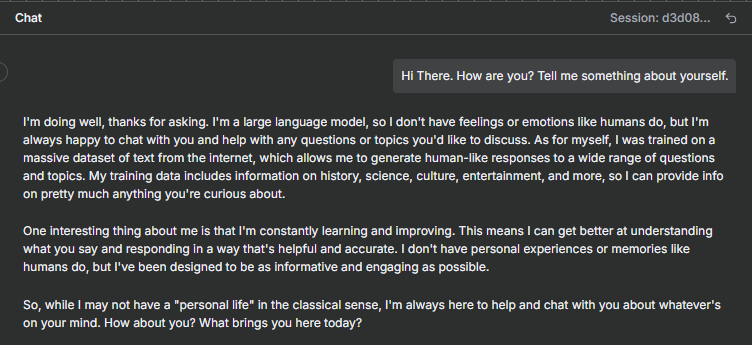
Your AI agent should respond instantly and remember what you've told it!
Next Steps
Want More Automation Ideas? Check out our N8N Automation Directory - a searchable database of real-world workflows you can implement.
Need More Detailed Guides? Visit our Frameworks & Guides section for comprehensive implementation tutorials.
Common Issues?
- If connection fails, make sure Ollama is running (check your system tray/menu bar)
- Try restarting both n8n and Ollama
- On some systems, you might need to use
http://172.17.0.1:11434instead of the host.docker.internal address
CG Strategy Lab explores practical AI implementation insights that bridge strategy and execution. Share your comments here and connect with me on LinkedIn if you'd like to discuss this topic further.
![Advanced Vibe Coding with Claude Code [Guide + Real Demos]](/content/images/size/w600/2026/02/Blog-Featured-Images...--1-.png)

![Practical Guide to Learning AI: From Tokens to Agents [ebook]](/content/images/size/w600/2025/08/Blog-Featured-Images...--4-.png)
